Задача: написать консольную утилиту, которая считает количество строк с кодом и использованных ключевых слов заданного языка программирования.
Например, для Python это выглядит так.
def main():
"""Главная функция приложения"""
print('hello, world!')Здесь будет всего 4 строки, из них 2 с кодом, потому что вторая это так называемый docstrings, а последняя пустая и её тоже не считаем. Ключевых слов использовано одно: def (определение функции); print это встроенная в язык функция, но не ключевое слово.
С одной стороны программа учебная, с другой, её можно со временем развивать, а значит сразу стоит предусмотреть архитектуру, которую потом не придётся полностью переписывать. Я решил построить приложение через workspace, который включает два крейта:
pyline-cli— бинарный файл, отвечает за взаимодействие с пользователем в консоли, и подготовку задачи для обработки;pyline-libs— библиотека, где собраны все методы сбора и обработки файлов.
Получается такой фронт и бэк. Фронт при желании можно сделать другой. Например, оконное приложение, а под капотом останется таже библиотека для обработки файлов.
Pyline-Cli
Задача консольного приложения — провзаимодействовать с пользователем и передать библиотеке сформулированное готовое задание.
pub fn read_cmd_args() -> ArgsResult {
let args = Args::parse();
let path = parse_path(args.path);
ArgsResult {
path,
auto_config: args.auto_config,
dirs: args.exclude_dirs,
marker_files: args.marker_files,
ignore_dot_dirs: args.ignore_dot_dirs,
extension: args.ext,
filenames: args.exclude_files,
lang: args.lang,
skip_gather_errors: !args.no_skip_gather_errors,
verbose: args.verbose,
}
}Благодаря внешнему крейту clap, мы избавлены от большого количества рутины, и можем сосредоточиться только на проверке полученных данных. Например, базовый способ запустить программу выглядит так:
> pyline --lang python --auto-configМы не передали ключ --path, с помощью которого определяется каталог для анализа. В этом случае программа автоматически подставляет каталог, где была запущена. Если же путь был передан:
> pyline --lang python --auto-config --path C:\CodeБлагодаря тому, что с помощью clap мы сразу обернули путь в Path, то проверка его валидности требует лишь нескольких команд и не нужно тратить свои силы на создание механики парсинга переданной строки, её преобразования в путь к каталогу, да ещё с учётом кросс-платформенных особенностей.
Таким образом, pyline-cli предоставляет библиотеке гарантированно корректные данные для дальнейшей работы. Ведь если пользователь допустил ошибку при использовании ключей, он сразу получит об этом сообщение и программа остановится. Например, на попытку запросить анализ языка, который ещё не поддерживается.
PS C:\Code> pyline -l java -a
error: invalid value 'java' for '--lang <LANG>'
[possible values: python, rust]
For more information, try '--help'.
PS C:\Code>Pyline-libs
Библиотека это ядро программы. Оно выполняет две основные функции:
- во-первых, в переданном каталоге нужно найти все файлы, соответствующие условиям (например, исключив осмотр отдельных каталогов или отбирать файлы только с определённым расширением);
- во-вторых, непосредственный анализ собранных файлов.
Для большей производительности, приложение использует асинхронный режим. Ссылки же на файлы собираются классическим способом: с помощью рекурсии.
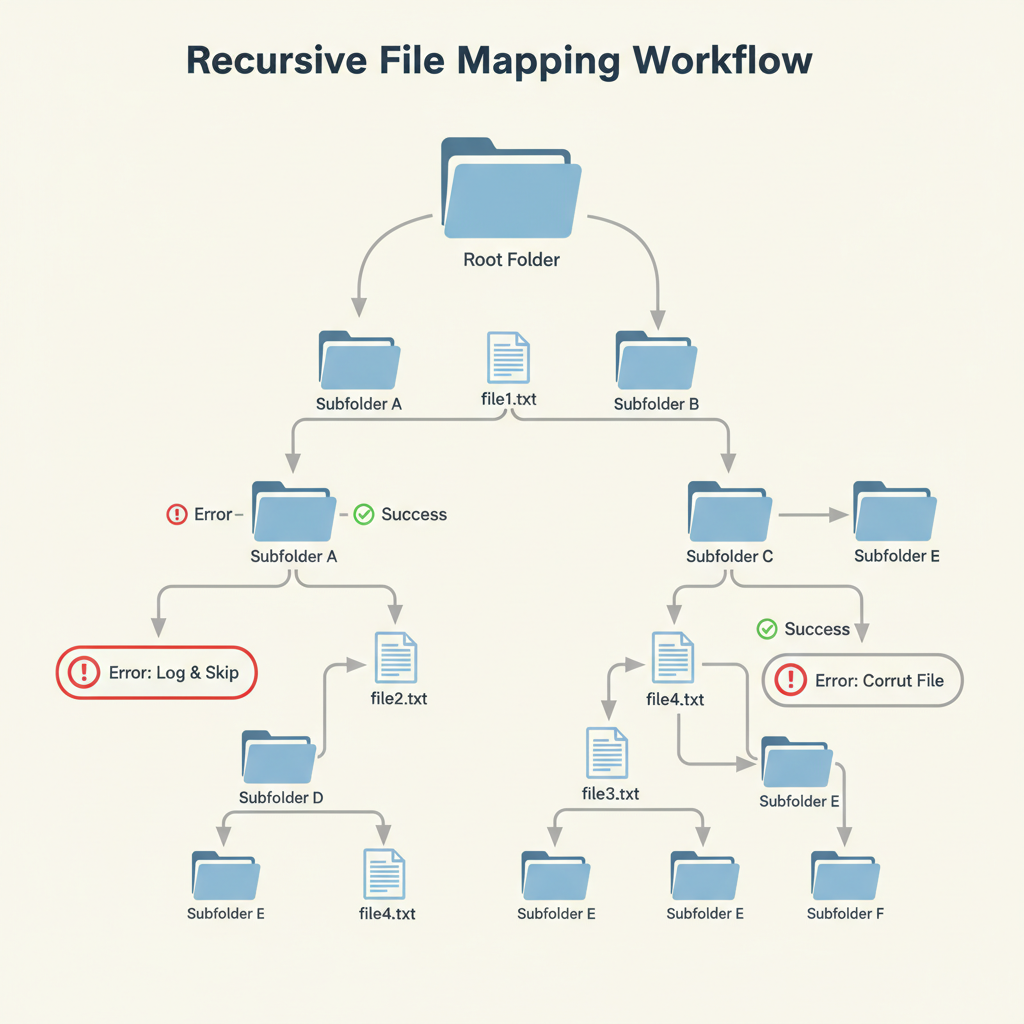
Проще говоря, функция вызывает саму себя, передавая в качестве аргумента путь к новому найденному каталогу. Таким образом, сначала программа уходит на максимальную глубину, а затем в обратную сторону все вызванные функции возвращают результаты и начальная собирает это в одну коллекцию.
Плюс рекурсии — минимальное количество кода, и одинаковая логика для всех проверяемых путей. Минусы тоже есть: там и вопросы производительности, и ограничения на глубину рекурсии и т.д., но для большинства ситуаций решение оптимальное.
Если сборка файлов прошла успешно, то мы получаем массив с валидными данными о каждом файле. Вот структура, экземпляр которой создаётся для файла.
#[derive(Debug, Default)]
pub struct FileData {
pub path: PathBuf,
bytes: u64,
}Здесь path — это полный путь к файлу, а bytes — его размер в байтах. Теперь необходимо проанализировать каждый файл, посчитать строки и разобрать каждую строку на составляющие.

Parser.rs
Написаны тысячи вариантов парсинга кодовых файлов и я не изобрёл новый алгоритм, конечно, но реализовал его самостоятельно. Ниже фрагмент кода, а потом небольшой разбор.
match (in_triple_quotes, ch) {
(false, '#') => { ... }
(true | false, '\'' | '"') => {
if is_triple_quotes(&mut chars, &ch, i) { ... }
buf_keyword.clear();
}
(false, ' ' | '\t' | '=' | ... ) => {
buf_keyword.clear()
}
(false, _) => {
buf_keyword.push(ch);
match Self::parse_keywords(&buf_keyword) {
Some(keywords) => {
*code_map.entry(keywords).or_insert(0) += 1;
buf_keyword.clear();
}
None => {
continue;
}
}
}
_ => continue,После открытия файл считывается построчно. Пустые строки откидываются сразу, а те, которые содержат данные, анализируются. Если выясняется, что строка состоит из комментария (например, в Python начинается с #), то она также отбрасывается.
Валидные строки читаются посимвольно, пока не найдётся совпадение с ключевым словом, либо возникнет условие при котором буфер обнуляется и начинается набор заново.
Например, вот строка кода:
if not news_item or not news_item_keys:Буфер будет наполнен 6 раз:
ifnotnews_itemornotnews_item_keys
Когда парсер будет считывать пробел, а для данной строки ещё и двоеточие, буфер сброситься. Выделенные жирным — это ключевые слова Python, и они будут засчитаны, а переменные news_item и news_item_keys пропущены.
Благодаря асинхронному режиму файлы будут анализироваться параллельно, а не последовательно, что на большинстве современных систем существенно повышает производительность.
Вот так в консоли выглядит работа pyline по анализу самой себя:
PS C:\Code\pyline> pyline -l rust -a
Selected language: Rust, https://rust-lang.org/
The files in the directory are being examined: C:\Code\pyline
Gathering files for analysis... .OK.
Successfully gathered 19 files.
Gathering code stats... OK.
Files: 19
Lines: 2742
of which are code lines: 1881
Keywords:
self = 167
Self = 159
in = 127
fn = 103
let = 95
pub = 90
mut = 73
use = 69
if = 46
as = 37
impl = 30
await = 28
bool = 24
match = 21
false = 19
else = 18
mod = 17
usize = 13
const = 11
while = 7
enum = 6
do = 6
u64 = 6
continue = 4
static = 2
f64 = 2
type = 2
PS C:\Code\pyline>Найдено 19 файлов (соответствующих фильтру), в них 2742 строки, из них содержащих код признаны 1881 (остальные либо пустые, либо это комментарии, например). Самое используемое ключевое слово: self.
Проект хранится в открытом репозитории с подробной документацией: https://github.com/Shindler7/pyline